
Nous avons longtemps attendu la version 4 d’ITIL. En attendant, nous avons pour beaucoup pallié aux manques d’ITIL et trouvé des arrangements avec l'écriture d’ITIL pour répondre aux problématiques de nos clients : que ce soit l’arrivée du Cloud sous toutes ses formes, le positionnement des productions en agrégateur de services, la généralisation des pratiques de développement Agile (pour répondre aux exigences des clients d’un time to market réduit de leurs applications), ou encore, l’adoption du DevOps pour répondre à la fracture culturelle des équipes de Dev et de Prod (et souvent à tort limité aux pratiques Agiles).
Le teasing sur ITIL 4 a été très efficace, probablement trop. Du coup, grand sentiment de stupéfaction à la découverte des premiers contenus publiés, surtout lorsque l’on passe vaillamment nos certifications Foundation. Nous avons carrément changé de populations cibles. Les concepts et la mise en perspective de l’apport de valeur, l’approche holistique, les 7 pratiques sont à la fois riches et intellectuellement séduisants… mais tellement éloignés des problématiques terrains de nos clients. Donc disons le carrément, stupéfaction et finalement déception au premier abord. Pas de trace de propositions de mises en pratiques autour du Lean, de l’Agile ou de l’approche DevOps.
Chez Timspirit, nous avons la conviction qu’il faut aller plus loin et, surtout, dépasser cette première impression. C’est la raison pour laquelle nous vous proposons de partager quelques éléments choisis issus des documents rarement lus de description de chacune des Practices. Nous allons donc commencer par mettre en exergue de manière totalement subjective des méthodes, propositions d’approches que nous estimons remarquables.
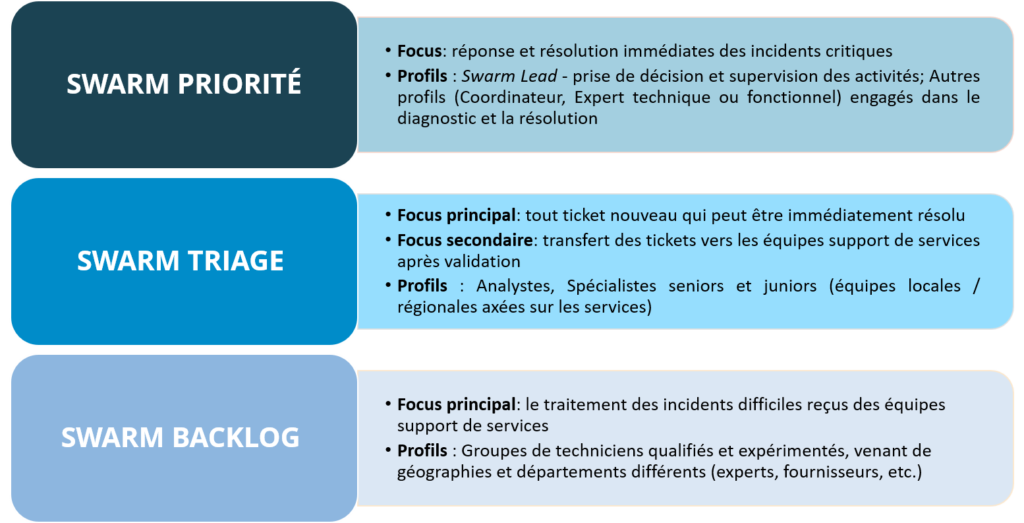
Gestion des incidents : ce que nous retenons
Flux de valeur de la gestion des incidents
Le flux de valeur de la gestion des incidents est concentré sur la résolution rapide et efficace des dysfonctionnements mais aussi assuré par l’effort collectif d’adaptation continue aux différents types d’anomalies qui peuvent émerger. Il existe plusieurs schémas d'activités clés pour résoudre les incidents, mais nous ne savons avec certitude qu'après la résolution quelle action a produit le bon résultat.
La résolution de chaque type d'incident peut être, en réalité, un processus distinct. Voici quelques exemples : d’un côté nous avons les incidents qui peuvent être résolus dès qu’ils sont détectés. Pour ce cas, on peut avoir définis des modèles d’incidents pour les gérer efficacement. Les exemples typiques ? Des incidents dus à des erreurs connues où les étapes de résolution sont documentées.
De l’autre côté, nous avons les incidents nécessitant plusieurs itérations pour les classifier, diagnostiquer et résoudre. De tels incidents ont tendance à être plus rares et n’ont probablement pas été rencontrés auparavant. Un exemple assez souvent rencontré : une application semble ne pas être réactive pour les utilisateurs, mais il n’y a aucune preuve dans les logs ou à partir de tout dispositif de surveillance que l’un des composants du système est en faute. Lorsque l’infrastructure est multicouche et complexe, il est nécessaire de reproduire l’incident afin de comprendre ce qu’il faut faire pour le résoudre.
Des méthodes comme le swarming, le modèle Cynefin et le principe fail fast, fail safe iterratively sont mis en avance pour une bonne compréhension de la complexité des incidents et la prise des décisions adaptées en termes d’efforts de résolution.
Zoom sur le SWARMING (un conseil, ouvrez vos chakras 😉 )
Nous vous proposons de descendre dans les explications autour d’un nouveau schéma de résolution des incidents : le SWARMING.
SWARM signifie un essaim d’abeilles. Il semble, dans certaines situations, doué d’une vie propre, tellement la synchronisation et la complémentarité des membres de cet essaim est parfaite. Nous pouvons imaginer sans peine la performance collective ainsi obtenue par un tel “essaim” d’êtres humains.
Le Swarming est donc une approche collaborative qui modifie de nombreux aspects de la gestion des incidents. Il n'y a pas d'escalade entre les différents niveaux de support. Au lieu de cela, quiconque pourrait être en mesure d'aider, a la possibilité de rejoindre le SWARM. Le point clé ? La collaboration entre de nombreuses ressources aux compétences variées et pertinentes pour aboutir à un diagnostic et à une résolution plus rapide et plus précise des incidents.

Mais qui sont les premiers à avoir adopté le modèle Swarming ? Ce sont principalement les organisations qui ont adopté les pratiques Agile / DevOps (comme BMC, Cisco) et qui témoignent avoir connu une amélioration sensible des services rendus. Les bénéfices sont notamment la visibilité accrue des cas au sein des équipes, une collaboration améliorée, des temps et délais de résolution réduits, une augmentation de la résolution au premier contact et, un renforcement du transfert de compétences et de connaissances.
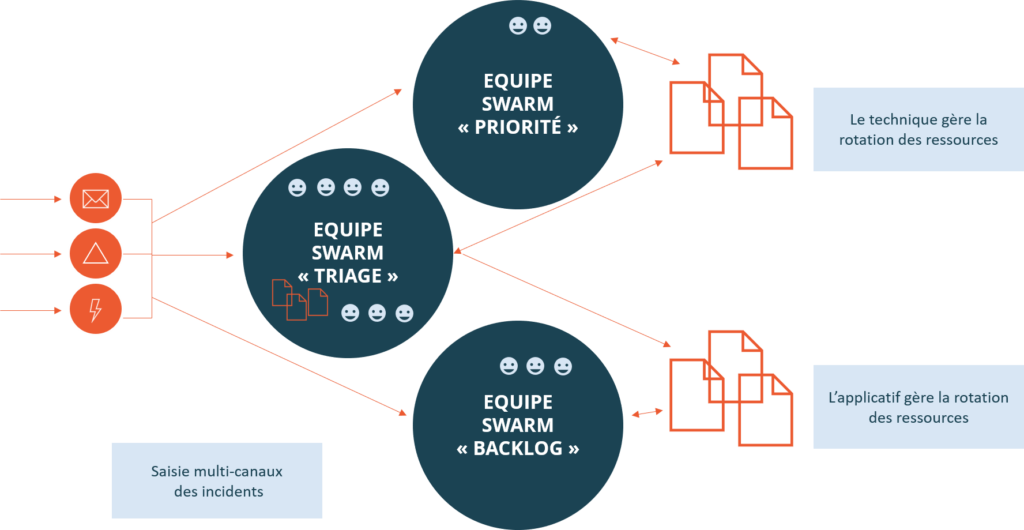
Exemple de flux de travail utilisant le modèle Swarming
Le modèle de support Swarming devient pertinent dans les environnements où des transformations business rapides ont conduit à l'adoption de pratiques Agile et DevOps ou lorsqu'une évaluation de l'état actuel de l’organisation des services informatiques montre des performances médiocres. C’est le cas par exemple sur les escalades répétées des incidents, le temps de résolution relativement long par rapport aux moyennes de l'industrie et la faible résolution au premier contact, ou encore, avec un taux élevé d’incidents transférés aux groupes techniques et applicatifs.
Un modèle simple de structure collaborative pourrait regrouper 3 types de Swarm, avec des équipes dont les membres se concentrent sur la résolution rapide et en temps réel des incidents. Le Swarm commence dès qu'un incident n'est pas immédiatement résolu lors du contact initial.
Une représentation du flux de la gestion des incidents en utilisant l’approche Swarming :
Mais quels sont les avantages du Swarming ?
- Evaluation et indicateurs (KPI) de l’équipe sont prioritaire par rapport aux individuels.
- Réduction de la dette technique (résolution au premier contact) et des transferts.
- Augmentation de la satisfaction utilisateurs grâce à la réduction des délais de résolution.
- Rétention des employés et productivité augmentées grâce au partage des connaissances et à la réduction du travail répétitif.
Challenges du Swarming
- Au niveau du leadership –Le Swarming peut être perçu comme risqué, complexe, difficilement réalisable sans des changements organisationnels considérables et, coûteux.
- Au niveau des coûts - Nous avons souvent l'impression qu'un modèle Swarming implique des ressources qui coûtent davantage par rapport au modèle traditionnel à plusieurs niveaux. Un contre-argument repose sur le fait que le Swarming offre un avantage à long terme, soit dans la réduction globale du travail, soit grâce à un meilleur engagement à long terme du support N1. Cela peut être quand même difficile à prouver.
- Au niveau de l’évaluation de la performance - Le swarming est plutôt un modèle conversationnel qu’un exercice de réaffectation des tâches. Pour de nombreuses organisations, il s'agit non seulement d'un simple défi de mesure mais également d’un défi financier. Dans des environnements où des bonus et pénalités sont établis, le passage à une nouvelle pratique de travail impose plus qu'un simple changement culturel : défaire et remplacer les accords contractuels existants et les offres de services standard.
D’autres pistes intéressantes mais moins explorées…
Une des questions majeures qu’on se pose aujourd’hui : comment maintenir le temps de disponibilité et la qualité des services dans le monde de la Continuous Integration / Continuous Delivery (CI / CD), de la propriété du code et des tests proactifs ? Une stratégie rigoureuse de réponse et de gestion des incidents est à envisager.
Détection
Sans une stratégie de détection, les vulnérabilités et les incidents de production ne peuvent pas être rapidement identifiés. La supervision continue rend les applications et l’infrastructure observables, améliorant ainsi la détection globale des incidents. L'ajustement continu des outils de supervision (tels que New Relic, Splunk, Prometheus ou Clever) et des règles d'alerte offre un suivi cohérent des systèmes et des notifications appropriées aux groupes concernés. A présent, une stratégie Digital Experience Monitoring (DEM) offre une vue complète de l'expérience utilisateur et recueille des données de chaque couche de la chaîne de livraison aidant à réduire le temps de détection.
Réponse
La réponse aux incidents consiste à prendre les informations obtenues au cours de la phase de détection, à les rendre transparentes et à trouver des moyens de collaborer en temps réel. Avec un service de diagnostic automatisé, les robots logiciels (RPA – Robotic Process Automation) peuvent sélectionner les incidents qui seront résolus par des algorithmes simples et transférer aux experts ceux qui nécessitent une prise de décision plus complexe. Compte tenu de la disponibilité 24h/24 et 7j/7 des ressources informatiques virtuelles, l'automatisation réduit considérablement le temps moyen de résolution et de réponse, augmentant ainsi la satisfaction du client.
Examen continu
Les analyses post-incidents représentent de multiples opportunités ! Apprendre des échecs, aller à la racine des problèmes et améliorer la façon dont on réagit aux incidents. Cela nécessite, dans un contexte de no blame culture, un changement d’approche de "Qu'avons-nous fait de mal ?" vers "Qu'avons-nous appris ?".
Surveillance proactive et tests
La surveillance proactive ou synthétique est une des pratiques DevOps qui offre un moyen d’enregistrer l’expérience réelle de l’utilisateur afin que tout problème ou écart de performance puissent être détecté et corrigé avant que l’utilisateur ne le rencontre. Pour une détection / réponse rapide et une bonne compréhension de la performance continue des systèmes, la surveillance devrait être mise en place non seulement dans les environnements de production (tests exploratoires, de contrainte, de charge, Automated Test Framework / ATF vs tests de régression), mais aussi dans ceux de développement, recettes et préproduction.
Antifragilité
Comment peut-on améliorer les systèmes pour détecter les incidents plus tôt, les résoudre plus rapidement et nous assurer qu'ils ne se reproduisent pas ? Comment passer d’un système fragile à un système robuste ?
Un concept original (au moins pour ceux qui ne se sont pas encore penché dessus), l’antifragilité (ou grandir et apprendre du désordre) introduite par le philosophe Nassim Nicholas Taleb, pourrait répondre à cette question.
Site Reliability Engineering (SRE) est la méthodologie utilisée par Google pour exécuter de gros systèmes de production de manière fiable. Netflix a développé Chaos Monkey pour tester la résilience de son infrastructure en provoquant des pannes (voir incidents) en environnement réel afin de révéler les vulnérabilités et les corriger.
Mais alors, comment Google et Netflix boostent l'anti-fragilité de leurs systèmes ?
- Meilleure compréhension des systèmes informatiques : aligner les objectifs business avec ceux techniques afin de créer des systèmes qui apprennent des erreurs et des interruption non prévues du service.
- Gestion efficace des incidents : se concentrer sur la façon dont la défaillance a pu se produire et sur la façon de l'empêcher de se reproduire à l'avenir (au lieu de trouver juste le coupable). Pour cela, il suffit :
- De documenter chaque incident ;
- D’identifier ce qui l’a généré (root cause) ;
- D’identifier des actions pour en réduire la probabilité de répétition et son impact.
- Adopter les meilleures pratiques de l’antifragilité - créer des contingences et des redondances via des services basés sur le cloud et multi-cloud, ajouter de la résilience architecturale par des approches de «conception pour l'échec / design for failure».
L’approche par la valeur a finalement du bon. Elle permet de reposer les principes de base que l’on a souvent oublié ou laissé de côté par habitude.